论文笔记:A Fine-grained Chinese Software Privacy Policy Dataset for Sequence Labeling and Regulation Compliant Identification
21. A Fine-grained Chinese Software Privacy Policy Dataset for Sequence Labeling and Regulation Compliant Identification
21.1 论文信息
- 作者:Kaifa Zhao, Le Yu, Shiyao Zhou, Jing Li, Xiapu Luo, Yat Fei Aemon Chiu, Yutong Liu
- 年份:2022年
- 会议:EMNLP
- 研究机构:The Hong Kong Polytechnic University
- 主要内容:构建首个中文隐私政策数据集 CA4P-483,包含 483 个 Android 应用的隐私政策及细粒度注释,推动中文隐私政策自动分析工具发展。
21.2 问题分析
现有隐私政策数据集主要面向英文,缺乏对中文隐私政策的支持。
21.3 研究方案
1. 数据集构建
(1)数据收集
- 使用 html2text 提取网页隐私政策;
- 使用 tagtog 进行标注。
(2)数据标注
参考中国《个人信息保护法》相关标准,定义七类标签:
- Data Controller:数据控制者;
- Data Entity:数据实体;
- Collection:数据收集;
- Sharing:数据共享;
- Condition:数据收集条件;
- Purpose:数据使用目的;
- Data Receiver:数据接收者。
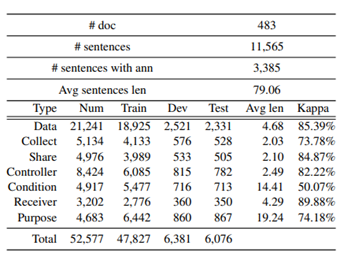
图21.1 CA4P-483数据集统计信息

图21.2 数据集示例
2. 分类测试
评估了 HMM、BiLSTM、BiLSTM-CRF、BERT-BiLSTM-CRF、Lattice-LSTM 等模型在该数据集上的性能。
- Receiver 准确率 > 90%;
- Collect & Share 准确率约 60%,因与其他标签存在重叠;
- Condition 易与 Purpose 混淆。
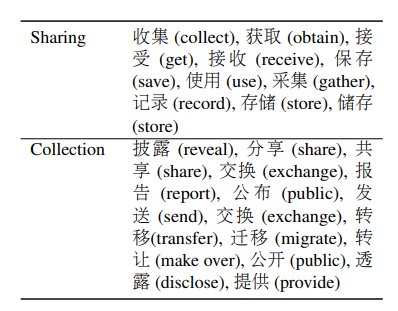
图21.3 动词列表
21.4 优缺点
优点
- 构建了首个中文隐私政策数据集,集成大量细粒度注释。
缺点
- 依赖数据收集和共享词汇定位相关句子,可能忽略枚举形式的条款。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yanjunbi's Blog!
