论文笔记:NLP-Based Automated Compliance Checking of Data Processing Agreements Against GDPR
19. NLP-Based Automated Compliance Checking of Data Processing Agreements Against GDPR
19.1 论文信息
- 作者:Orlando Amaral Cejas, Muhammad Ilyas Azeem, Sallam Abualhaija, Lionel C. Briand
- 年份:2023年
- 会议:IEEE Transactions on Software Engineering (TSE)
- 研究机构:University of Luxembourg
- 主要内容:提出了一种基于自然语言处理 (NLP) 的自动化方法 DERECHA,通过语义框架对 DPA 和 GDPR 进行短语级分解并进行比较,以检查数据处理协议是否符合 GDPR 规定。
19.2 问题分析
现有合规性检查工具存在以下不足:
- 粒度差异:DPA 粒度较细,而 GDPR 监管文本较粗,传统相似性分析无法准确反映两者之间的语义关系。
- 上下文缺失:多数方法只考虑表面相似性,忽略深层语义和上下文。
- 部分满足问题:某些声明可能部分满足多个 GDPR 要求,但现有方法无法识别。
19.3 研究方案
1. 合规性要求制定
根据法律专家建议,从 GDPR 中提取了 45 项规范 DPA 的合规性要求,分为四类:
- **元数据要求 (MD)**:共 9 项;
- **处理者义务 (PO)**:共 25 项;
- **控制者权利 (CR)**:共 3 项;
- **控制者义务 (CO)**:共 8 项。
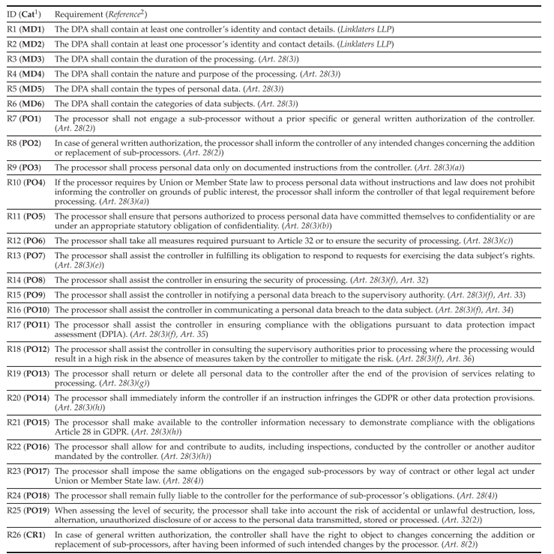
图19.1 强制性要求说明
此外,文中创建术语表帮助理解合规要求,并提供与 GDPR 条款的可追溯链接。
2. DPA 合规性检查的自动化方法
设计基于 NLP 的方法 DERECHA,用于在短语级别检查 DPA 是否符合 GDPR。
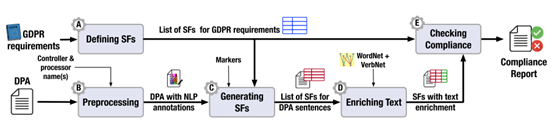
图19.2 DPA合规检测方法框架
(1)语义框架定义(SF)
定义十个语义参数:
- Action, Actor, Object, Constraint, Beneficiary, Reason, Time, Condition, Situation, Reference
构建谓词-参数结构表示合规要求。
(2)DPA文本预处理
采用标准 NLP pipeline:
- Tokenization
- 句子拆分
- 词形还原
- POS标注
- 分块
- 依存句法分析
- 语义分析(WordNet + VerbNet)
(3)自动生成 SF 表示
为每条 DPA 语句生成 SF 表示。提出一组规则识别 SR,基于依赖解析树匹配语法角色。
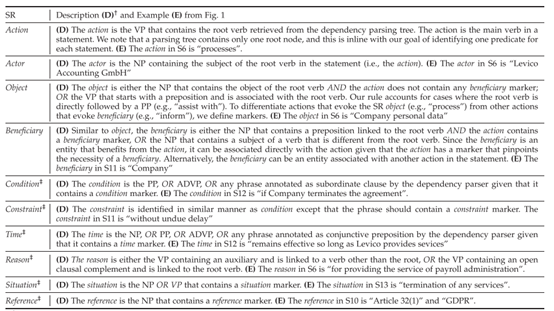
图19.3 提取SR的规则
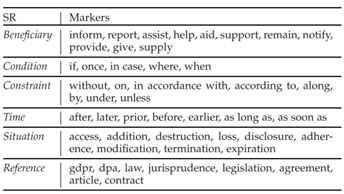
图19.4 用于识别语义角色的标记
(4)丰富 DPA 文本内容
- 利用 WordNet 提取同义词;
- 借助 VerbNet 扩展动词;
- 替换具体实体为通用表述(如“the controller”)。
(5)合规性检查流程
- 对 R1、R2 使用正则表达式提取联系信息;
- 对 R3–R6 和 R27–R29 使用 Lesk 算法判断词义重叠;
- 对其余要求使用 SF 匹配方法:
- 比较谓词(动词或 WuP 相似度);
- 参数匹配(Jaro-Winkler 距离);
- 最终判断是否满足某项要求。
图19.5 合规性检测示例
19.4 优缺点
优点
- 提出了一种适用于多种法规的自动化合规检测方法。
缺点
- 使用的 WordNet 未覆盖隐私法规领域专有名词,影响准确性。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yanjunbi's Blog!
