论文笔记:A BERT Based Approach to Measure Web Services Policies Compliance With GDPR
14. A BERT Based Approach to Measure Web Services Policies Compliance With GDPR
14.1 论文信息
- 作者:Hao Cui, Rahmadi Trimananda, Athina Markopoulou, Scott Jordan
- 年份:2021年
- 期刊:IEEE Access
- 研究机构:University of Maryland at Baltimore County
- 主要内容:提出了一种检测 Web 隐私政策与 GDPR 合规性的方法。使用 BiLSTM 多分类模型识别 GDPR 类别,并结合 BERT 模型提取上下文表示,计算隐私政策与 GDPR 的相似度得分,判断其是否合规。
14.2 问题分析
企业在制定隐私政策时面临以下挑战:
监管文件内容庞大且复杂:
- GDPR 包含 99 篇文章,人工提取关键规则耗时费力。
隐私政策与法规长度差距大:
- 隐私政策文本较短,难以直接关联到法规条目。
14.3 研究方案
1. 监管文档(GDPR)知识图谱构建
确定了四个核心实体:
- Controller(控制者)
- Processor(处理者)
- Data Subject(数据主体)
- Supervisory Authority(监管机构)
通过命名实体识别(NER)提取这些实体并填充到知识图谱中。同时将句子分为两类:Permissions 和 Obligations。
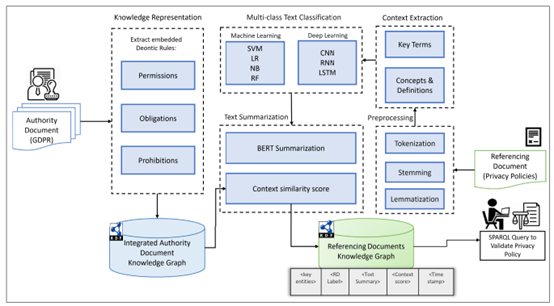
图14.1 方法架构图
2. 构建隐私政策语料库
爬取了 3000 多个符合 GDPR 的隐私政策文档,并提取上述四类实体信息。
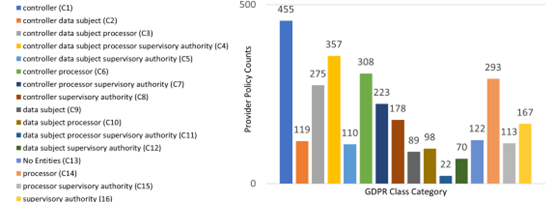
图14.2 语料库分布情况
3. 隐私政策文本分类
使用多种机器学习和深度学习模型进行多类分类实验:
- 浅层模型:朴素贝叶斯、随机森林、逻辑回归、支持向量机;
- 深度模型:CNN、LSTM、BiLSTM。

图14.3 文本分类模型结果
结果显示,深度学习模型在小文本数据集上表现更佳。
4. 隐私政策摘要生成
采用 BERT 分词器对隐私政策分句,输入预训练 BERT 模型生成嵌入向量,再用 K-Means 聚类提取最相关句子作为摘要。
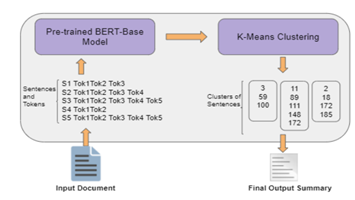
图14.4 文本摘要方法
5. 隐私政策知识图谱构建
使用 Protégé 工具构建知识图谱,定义类 Web_Service_Provider,包含:
- GDPR 类别预测;
- 摘要;
- 与法规的相似度得分(余弦相似度)。

图14.5 知识图谱示例
14.4 优缺点
优点
- 提出基于 BERT 的框架,自动匹配隐私政策与 GDPR 条款;
- 使用 BERT 进行摘要提取,能保留更多语义信息。
缺点
- 对隐私政策的整体审核不够细致,未深入分析收集的数据类型范围。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yanjunbi's Blog!
