论文笔记:Consistency Analysis of Data-Usage Purposes in Mobile Apps
10. Consistency Analysis of Data-Usage Purposes in Mobile Apps
10.1 论文信息
- 作者:Duc Bui, Yuan Yao, Kang G. Shin, Jong-Min Choi, Junbum Shin
- 年份:2021年
- 会议:ACM Conference on Computer and Communication Security(CCS)
- 研究机构:University of Michigan
- 关键词:Data-usage purposes; privacy policies; consistency analysis; data flow; mobile apps
- 主要内容:提出了一种自动化系统 PurPliance,用于检测隐私政策与 Android 应用实际行为之间在数据使用目的上的不一致性,并可分析隐私政策内部条款之间的矛盾。
10.2 问题分析
尽管隐私政策中通常列出数据的使用目的,但应用实际行为可能与其声明不符。这种不一致性严重影响用户隐私保护,然而一致性分析面临以下问题:
- 数据使用目的解析不足:已有研究未从“数据使用目的”角度解析隐私政策,导致一致性分析误报率高。
- 目的从句复杂:隐私政策中的目的表达冗长且形式多样,难以提取和解析。
- 低级别数据流语义缺失:应用程序的数据流发生在底层,缺乏高层次语义信息,使得推断数据流的目的极具挑战性。
10.3 研究方案

图10.1 PurPliance 系统工作流程
1. 提取隐私政策中的数据使用目的
PurPliance 利用语义角色标注(SRL)、句法分析和动词列表提取隐私政策中描述的数据活动及其使用目的。
- SCoU 动词识别:基于手动整理的共享-收集-使用(Sharing-Collection-or-Use)动词列表;
- 目的子句提取:利用 CoNLL2012 定义的规范识别“to + verb”、“in order to”等形式的句子。

图10.2 SCoU动词列表

图10.3 从语义角色到隐私声明参数的映射示例
2. 隐私目的分类
(1)提取非复合目的(Uncompounded Purpose)
将复杂目的子句拆分为单一目的,表示为谓语-宾语(PO 对)形式。
图10.4 PO对示例
(2)构建目的分类方法
使用 RoBERTa 将目的嵌入向量空间,通过 K-means 聚类提取 15 个具体类别 + 1 个其他类别;并结合商业行为定义了 5 个高抽象级别分类。
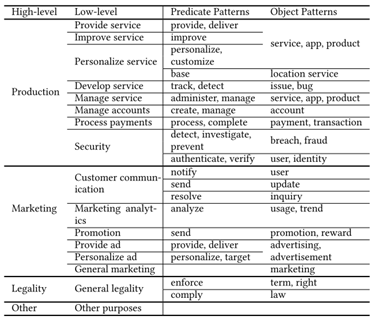
图10.5 目的分类方法
(3)数据使用目的分类器
基于 PO 对训练多分类模型,在 198,339 个目的子句上达到平均精度 97.8%。
3. 隐私声明提取
**隐私声明表示为二元组 (dc, du)**:
- dc = (r, c, d):数据收集,表示接收方 r 是否收集数据对象 d;
- du = (d, k, p):数据使用,表示 d 是否用于目的 p。
实体敏感数据使用目的(entity-sensitive data usage purpose)
表示为 (e, q),其中 e 是服务实体,q 是目的类型。
隐私声明参数提取步骤:
- 识别数据活动谓语;
- 使用 SRL 提取语义论元;
- 将论元映射为正式参数(r, c, d, k, e, q)。
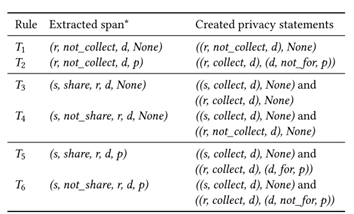
图10.6 从 text span 创建隐私声明
4. 数据流提取
数据流三元组:(r, d, p)
表示接收者 r 收集数据对象 d 用于目的 p。
数据流来源:
- 来自网络请求的键值对;
- 接收方 r 通过 URL、包名等解析;
- 目的服务实体 e 基于 r 和 q 推断。
分类实验结果:
- 数据类型分类:随机森林模型 F1 = 95%,精确率 = 97%,召回率 = 93%;
- 数据流目的推断:F1 = 79%,精确率 = 81%,召回率 = 78%。
5. 一致性分析
(1)语义关系建模
引入语义等价、包含、近似等概念,构建本体映射。
(2)隐私声明矛盾检测
扩展 PoliCheck 模型,定义逻辑矛盾和缩小定义两种矛盾类型。

图10.7 矛盾规则
(3)数据流一致性条件
- 存在性条件:存在 ct=collect 且 kt=for;
- 否定条件:存在 ct’=not_collect 或 kt’=not_for。
10.4 实验评估
1. 数据集
- 应用程序:共 35,000 个独特 Android 应用;
- 隐私政策:16,802 份,140 万条句子;
- 网络流量:1,727,001 条请求,来自 17,144 个应用。
2. 隐私声明和数据流分析
- 抽取 874,287 个隐私声明;
- 提取 701,427 个数据流;
- 最常见目的是“提供服务”和“改善服务”。
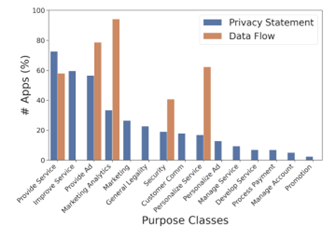
图10.8 隐私声明和数据流的用途分布情况
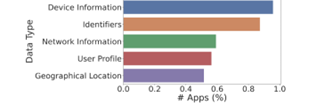
图10.9 数据流的数据类型分布
3. 隐私政策矛盾检测
人工标注 108 份政策,发现 189 对矛盾句。
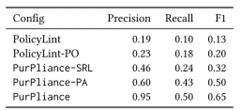
图10.10 矛盾检测结果
4. 数据流到隐私政策的一致性分析
- 检测到 29,521 对潜在矛盾;
- 不一致数据流 95,083 个,占比 13.56%;
- 最常见矛盾类型为 C1 和 N1。
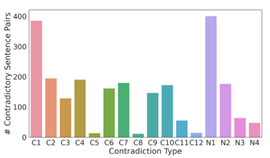
图10.11 特定于目的的矛盾类型的分布情况
10.5 优缺点
优点
- 提取 PO 对实现自动分类数据使用目的;
- 提出覆盖更广的隐私声明表示方法;
- 形式化定义隐私政策矛盾与数据流一致性。
缺点
- SRL 模型性能受限,影响抽取准确率;
- 无法处理 SSL 加密或需登录的 APP 行为。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yanjunbi's Blog!
