论文笔记:Towards Automated Regulation Analysis for Effective Privacy Compliance
3. Towards Automated Regulation Analysis for Effective Privacy Compliance
3.1 论文信息
- 作者:Sunil Manandhar, Kapil Singh, Adwait Nadkarni
- 年份:2024年
- 会议:Network and Distributed System Security (NDSS)
- 研究机构:IBM T.J. Watson Research Center
- 主要内容:提出 ARC 方法,将法规文本结构化为元组形式,并开发 ARCBert 模型用于识别相似短语,从而简化法规比较过程。同时扩展 ARC 用于隐私政策合规性分析。
3.2 问题分析
分析隐私法规面临两大挑战:
- 法律术语难以理解,需了解每项法规特有词汇;
- 法规陈述依赖上下文,表达相同概念时表述差异大,难比较。
3.3 研究方案
ARC 框架
旨在将非结构化法规文本转换为保留上下文的结构化元组,支持多法规分析和隐私政策分析。
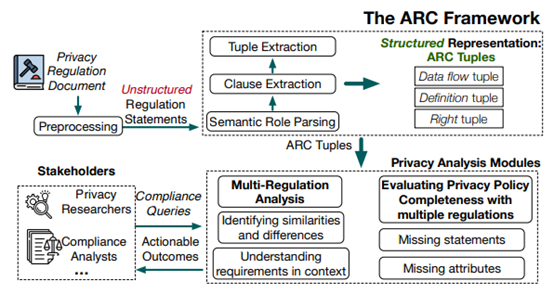
图3.1 ARC框架图
流程如下:
监管文本语义解析:
- 使用 HtmlToPlainText 预处理法规文件;
- 使用 BERT+SRL 提取 argument 及 verb sense。
从短语中提取子句:
- 使用 Benepar 获取短语结构树,简化语句。
提取 ARC 元组:
- Data Flow Tuple:⟨Sender, Deontic Modal, Data Flow Verb, Receiver, Data Object, Transmission Principles⟩
- Definition Tuple:⟨Definiendum, Definition Verb, Definiens⟩
- Right Tuple:⟨Entity, Deontic Modal, Right Verb, Right Statement⟩
映射元组参数:归入传输原则属性。
应用模块
- Multi-Regulation Analysis:识别法规间的相似性;
- Evaluating Privacy Policy Completeness:识别隐私政策中缺失披露项。
3.4 实验评估
1. ARC 元组评估
使用 CCPA、GDPR、PIPEDA、VCDPA 构建数据集。
- Data Flow Tuple F1-score:83.4%
- Definition Tuple:ARC 召回率优于 LexNLP,准确率略低;
- Right Tuple F1-score:81%
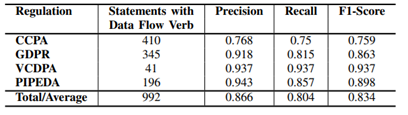
图3.2 Data Flow Tuple实验结果
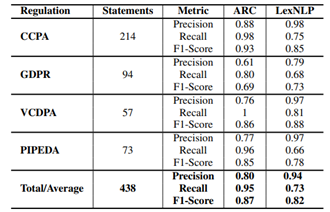
图3.3 Definition Tuple实验结果
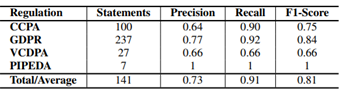
图3.4 Right Tuple实验结果
2. 多法规分析实验
训练基于 BERT 的模型 ARCBert,识别相似短语。
- ARCBert 表现优于 GloVe,更准确识别语义相似短语。
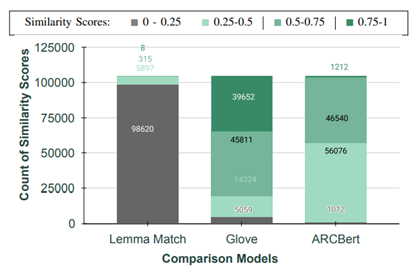
图3.5 PIPEDA与GDPR的相似性得分
3. 基于 Definition Tuple 的法规分析
比较 CCPA、GDPR、VCDPA 和 PIPEDA 的 definition tuple。
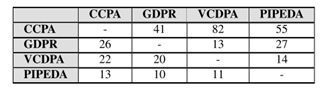
图3.6 基于Definition Tuple的相似性分析结果
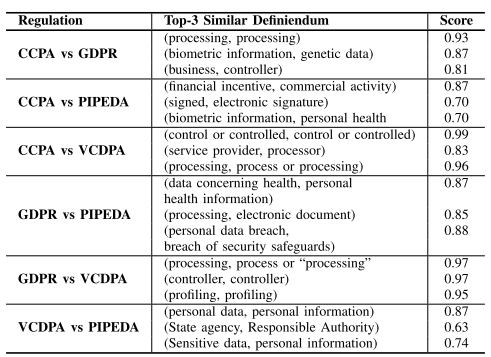
图3.7 各法规中最相似的3个定义
4. 方法普适性分析
在 16 个额外法规上运行 ARC,验证其泛化能力。
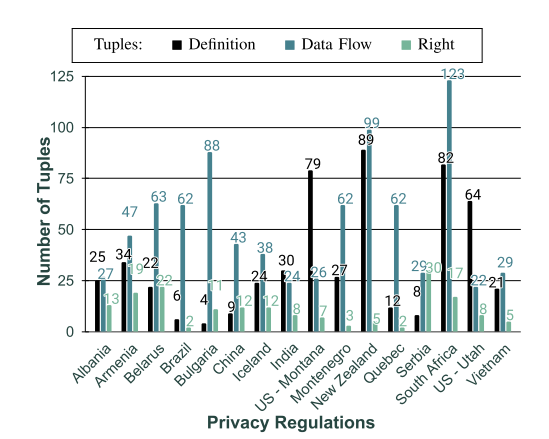
图3.8 ARC在16个法规上提取元组的结果
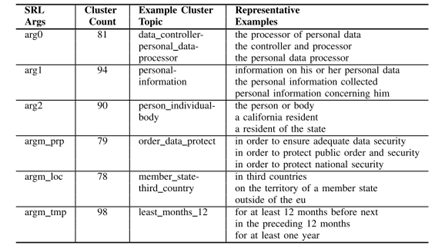
图3.9 20个法规的SRL参数聚类结果
5. 隐私政策合规性分析
数据集
从 S&P 500 公司获取 1,864 个隐私政策。
构建 Policy Segment 分类器
使用 OPP-115 数据集训练 BERT 模型,F1-score 为 86%。
元组分析维度
- 数据本体比较;
- 属性值比较;
- 属性存在性比较。
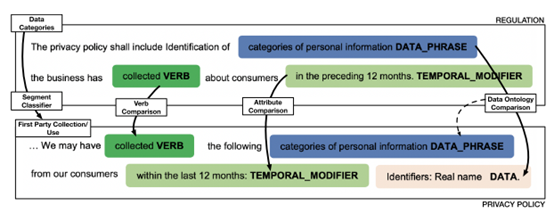
图3.10 合规性分析示例
合规性分析结果
共发现 476 处缺失陈述。
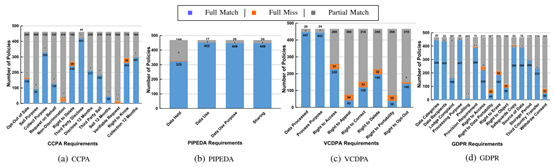
图3.11 S&P 500企业的合规性分析结果
手动验证结果
- 缺失语句准确率:72.12%
- 完全匹配准确率:90.13%
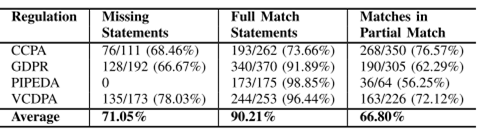
图3.12 隐私政策合规性验证结果
3.5 优缺点
优点
- 实现法规文本结构化表示;
- 支持法规相似性分析;
- 提升人工分析可靠性。
缺点
- OPP-115 数据集较旧;
- 关键词匹配忽略上下文;
- 忽略名词短语形式的数据流动词;
- “include”动词导致定义元组误报。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Yanjunbi's Blog!
